
티스토리 뷰
이번에 꽤 흥미로운 이슈를 하나 겪었다. 동일한 쿼리, 동일한 파라미터로 MyBatis 쿼리를 두 번 실행했는데, 첫 번째 쿼리의 결과와 두 번째 쿼리의 결과가 달랐다. (p6spy를 통해 확인했을 때 두 번째 쿼리는 로그조차 안 찍힘)
결론부터 얘기하자면, MyBatis의 1차 캐시 때문에 발생한 문제였다.
트랜잭션과 1차 캐시
트랜잭션 내에서 1차 캐시가 동작한다는 점을 이해하는 것이 중요하다. MyBatis에서 1차 캐시는 SqlSession 단위로 관리되며, 하나의 트랜잭션 내에서 같은 SqlSession을 사용하기 때문에 트랜잭션 동안 캐시된 데이터는 계속 유지된다. 이 말은 트랜잭션 내에서 같은 쿼리와 파라미터로 데이터 조회 시, 쿼리가 실행되지 않고 1차 캐시에서 결과를 가져온다는 의미다.
따라서 트랜잭션 내에서 같은 데이터를 여러 번 조회하는 경우, 1차 캐시로 인해 의도치 않은 데이터 오염이 발생할 수 있다. 예를 들어, 위의 경우에서는 빈 리스트를 처음 조회하고, 그 리스트를 수정했는데, 다시 조회 시 1차 캐시에서 수정된 리스트를 그대로 가져와 DB에는 없는 데이터가 포함된 리스트를 반환하게 되는 상황이 발생했다.
참고로 Mybatis에는 1차 캐시와 2차 캐시가 있다(https://codingdreamtree.tistory.com/92)
상황 정리
케이스를 간단히 요약해보면 아래와 같다
1. mapper를 통해 name=aaa인 데이터를 가지고 온다 -> 결과없음(0개)
2. 1을 통해 가지고 온 데이터를 리턴하고 이후 로직에서 1에서 리턴한 객체에 add 한다
3. aaa 유저를 다시 mapper를 통해 가지고 온다 -> 쿼리 로그 찍히지 않음, 결과는 1개
처음엔 이게 뭔가 싶었는데, 알고 보니 MyBatis는 동일한 쿼리와 동일한 파라미터로 요청이 들어오면 1차 캐시(Local Cache)에서 결과를 꺼내 반환하기 때문에 생긴 현상이었다. 문제는 1차 조회 결과(빈 리스트)를 그대로 반환해서, 이후 로직에서 그 리스트를 수정했다는 거다.
결국 3번 조회 시에는 쿼리를 날리지도 않고, 캐시에 있던 조작된 리스트를 그대로 반환해버린 것이다.
당연히 DB에는 없는 데이터인데도, 있는 것처럼 처리되는 상황이 되어버린 셈이다.
아래는 상황을 코드로 간략하게 재현해본 코드이다:
@Test
public void testFirstLevelCacheIssueWithLoop() {
String notExistUser = "notExistUser";
for (int i = 0; i < 2; i++) {
List<User> users = getUserListAndModify(notExistUser);
System.out.println("Loop " + i + " - users.size() = " + users.size());
users.add(new User()); // add() 수행
}
}
/**
* 유저 데이터를 조회하고, 내부에서 add() 수행
* 동일 쿼리와 파라미터 사용 시 1차 캐시 영향 받음
*/
private List<User> getUserListAndModify(String name) {
List<User> users = userMapper.getUserByName(name); // 1차 캐시 대상
return users;
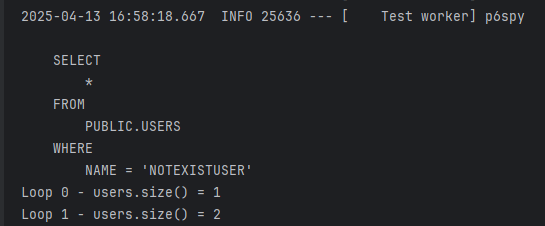
}로그를 확인해보면, 3번 쿼리는 아예 실행조차 되지 않는다.
1차 캐시에 의해 생략됐기 때문이다.
즉, users 리스트는 같은 객체고, add가 누적되면서 사이즈가 계속 증가한다.
실제로 DB엔 아무것도 없지만, 코드상에선 계속 유저가 생겨나는 상황이 된 것이다
해결 방안
1. 1차 캐시를 끈다(비추)
MyBatis에서는 SqlSession 단위로 1차 캐시를 사용한다.
필요하다면 아래처럼 캐시를 직접 초기화할 수도 있다:
sqlSession.clearCache();아니면 설정에서 캐시 범위를 좁힐 수도 있다:
<settings>
<setting name="localCacheScope" value="STATEMENT"/>
</settings>아니면 해당 쿼리에서만 캐싱을 하지 않을수도 있다:
<select id="selectUser" parameterType="int" resultType="User" flushCache="true">
<!-- Your SQL statement here -->
</select>하지만 이건 근본적인 해결책이라기보다는, 그때그때 문제점만 막는 것에 가깝고, 이로인해 어떤 사이드 이팩트가 발생할지 모른다.
2. 조회한 데이터를 직접 수정하지 않도록 한다(추천👍)
내가 겪은 이슈의 핵심은 "조회한 데이터를 로직에서 수정했다"는 데 있다.
1차 캐시는 동일한 객체를 리턴하기 때문에, 해당 객체를 수정하면 캐시도 같이 오염된다.
그렇기 때문에 가장 깔끔한 방법은, 조회한 데이터를 DTO 등으로 변환해서 리턴하는 것이다.
private List<User> getUserListAndModifySafely(String name) {
List<User> users = new ArrayList<>(userMapper.getUserByName(name)); // 복사본 생성
return users;
}이렇게 하면 원본 엔티티나 리스트를 직접 수정하지 않고, 캐시 오염을 막을 수 있다.

사실 이 코드도 문제가 있다 만약 users 의 결과가 있고, 그 데이터를 리스트에서 가져다 수정한다면 캐시에 있는 데이터는 또 오염될 것이다!
따라서 user도 deepcopy를 해야한다
private List<User> getDeepCopiedUsers(String name) {
return userMapper.getUserByName(name).stream()
.map(user -> new User(user)) // 복사 생성자
.collect(Collectors.toList());
}
최근엔 JPA로 개발을 진행하다 보니 MyBatis 쓸 일이 줄어들고 있다. 신입 친구들 중에는 MyBatis 한 번도 안 써봤다는 경우도 있어서 놀랐던 적도 있다. 내가 개발 중인 서비스는 오래된 MyBatis 기반의 코드와 새로 작성한 JPA 기반 코드가 공존하고 있는데, JPA에선 익숙했던 캐시 개념이 MyBatis에도 있다는 걸 새삼스럽게 다시 알게 된 계기였다.
실제 운영 중인 서비스에서 이런 캐시 오염 문제가 발생하면 꽤 위험할 수 있기 때문에, 조회한 데이터를 왠만하면 복사해서 리턴하는게 좋다는 교훈을 얻은 경험이었다.
'ㄴspring boot' 카테고리의 다른 글
| [Spring Boot] Multiple Datasource with Clickhouse (0) | 2024.06.17 |
|---|---|
| ThreadPoolExecutor RejectedExecutionException 오류 - SynchronousQueue (0) | 2023.07.11 |
| [spring boot] mybatis + jpa multi datasource 설정하기 (7) | 2021.02.15 |
- Total
- Today
- Yesterday
- docker
- 스레드 동기화
- API Gateway
- 카프카
- 네트워크
- s3
- cursor mcp
- CURSOR
- myabatis
- 쓰레드 변수
- 도커
- 캐시
- 기본클래스를 찾거나 로드할 수 없습니다
- volatile
- jpa 1차 캐시
- cleanup policy
- db 두개
- 1차캐시
- php
- AWS
- 넥서스 파일 보관주기
- multiple datasource
- 보관주기
- 오블완
- 다중 데이터소스
- PostgreSQL
- 넥서스 보관주기
- cleanup policies
- cursor ai
- spring boot
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |